Your Forward Deployed Engineers Don't Have an Operating System. They Should.
Sarah is the future of enterprise software delivery — brilliant, expensive, and completely unscalable. Unless you give her an operating system. The case for FDE infrastructure.
Your Forward Deployed Engineers Don't Have an Operating System. They Should.
Sarah flew to a financial services client for three weeks, embedded with their team, and built a custom Salesforce-to-Snowflake integration that no off-the-shelf tool could touch. She was brilliant, expensive, and—as far as anyone in leadership was concerned—completely unscalable.
What I didn't understand then is that Sarah is the future of enterprise software delivery. What I've come to understand since is that she's doing it with one hand tied behind her back.
Forward Deployed Engineering is the dominant model for deploying complex enterprise AI, data infrastructure, and defense technology. Palantir pioneered it in the mid-2000s. OpenAI, Anthropic, Databricks, Anduril, and Shield AI scaled it. Job postings for the role grew 1,165% year-over-year from 2024 to 2025, with demand spikes across every major AI lab[](https://bloomberry.com/blog/i-analyzed-1000-forward-deployed-engineer-jobs-what-i-learned/). The model works.
But the tooling for FDEs is stuck in 2012.
The $5M Wheel Reinvention Problem
A single FDE costs $174K–$325K annually in fully-loaded compensation. They spend 40–50% of their time on direct customer implementation, 20–30% on technical consulting, and the remainder feeding insights back to the core platform.
Here's what the job descriptions don't mention: a significant chunk of that implementation time is redundant.
FDE leads at AI labs and defense contractors tell the same story. Their engineers are building the same data transformation pipelines, the same API bridges, the same compliance adapters—customer after customer. One director put it plainly: "We're paying $300K for someone to reinvent a wheel we built last quarter."
For a 50-person FDE organization—$12.5M in annual fully-loaded cost—if 40% of implementation work is redundant, that's $5M in structural waste. Not incompetence. Not mismanagement. Structural waste baked into the model itself.
Palantir solved this through culture. Engineers in the field and engineers at HQ are deliberately indistinguishable in skill and context. Knowledge flows through intense documentation, internal tooling built over two decades, and a rotation system that keeps field learnings connected to the core platform. That's a viable solution if you're Palantir. It's not a solution you can copy-paste.
What FDEs Actually Need
When I started asking FDEs what would make them more effective, the answers weren't what I expected. They didn't ask for better onboarding or cleaner documentation. They described something that doesn't really exist yet: an operating system for their work.
Think about what a standard software engineer has access to. Package managers. CI/CD pipelines. Container orchestration. Observability stacks. A decade of investment in developer experience. Now think about what most FDEs have: a laptop, a customer VPN, and a shared Notion wiki that's three months out of date.
The infrastructure FDEs need solves three problems:
Pattern capture and reuse. When Sarah builds that Salesforce integration, the structure—the OAuth flow, rate limit handling, data quality checks—should be extractable, parameterized, and available to the next FDE facing the same challenge.
Hard customer isolation. FDEs work in defense networks, financial systems, and healthcare infrastructure. The platform cannot compromise customer boundaries for operational convenience. A bug in an internal developer platform affects internal services. A bug in FDE infrastructure could expose classified data.
Closing the Full Loop. FDEs generate enormous intelligence about what customers actually need. Most of it evaporates in Slack threads and post-mortems. The feedback path from field insight to platform improvement should be structural, not aspirational.
Why Kubernetes Operators Are the Right Foundation
After working through several architectural options, I keep landing on Kubernetes operators. Not because every FDE team runs Kubernetes—though many do—but because the operator pattern structurally mirrors what FDEs do.
An operator is infrastructure that manages infrastructure. It watches custom resources, reconciles desired state with actual state, and automates complex operational workflows. That is exactly what FDEs do: they observe customer environments, reconcile software capabilities with operational reality, and automate integration workflows.
The architecture centers on four custom resources:
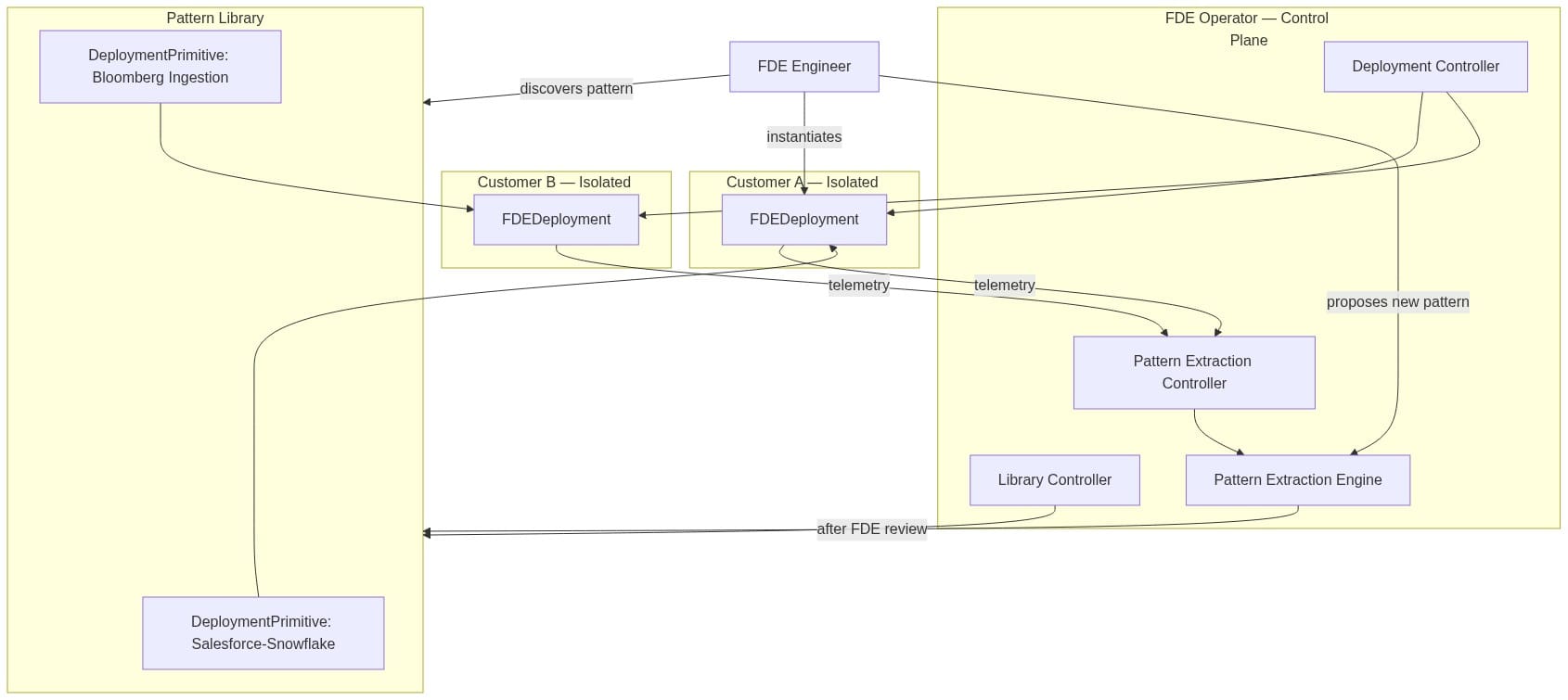
When an FDE needs a Salesforce integration, they don't start from scratch. They discover the primitive, instantiate an FDEDeployment with customer-specific parameters, and let the operator handle provisioning, monitoring, and lifecycle management. The customer namespace stays isolated. The deployment is tracked and observable.
Here's how the full system fits together:
The Pattern Extraction Engine is where the Full Loop becomes concrete. Telemetry feeds capture integration errors, performance signals, and custom code commits as FDEs work. The engine clusters similar challenges across deployments, identifies generalizable solutions, and proposes new primitives. FDEs review before publication. The library grows. Future FDEs start from a higher floor.
This Isn't an Internal Developer Platform
IDPs have had a good decade. They solve the golden path problem: standardize how developers deploy services, manage infrastructure, handle observability. They're genuinely useful.
FDE Infrastructure is a different problem.
IDPs optimize for internal developers on a shared platform. FDE infrastructure must maintain hard isolation between customer environments—separate network policies, separate secret stores, per-action audit logging. IDPs reward standardization. FDE work exists because standardization breaks down at the edge. The infrastructure has to embrace bespoke work, not resist it.
The deeper difference is what success looks like. An IDP's metric is developer velocity. FDE Infrastructure's metric is pattern reuse rate and Full Loop latency—how fast does a field insight become a reusable primitive? That's a fundamentally different optimization function.
The Adoption Problem Nobody Wants to Admit
Here's what I got wrong initially: I assumed FDEs would welcome this infrastructure. Many won't.
The best FDEs are craftspeople. They take pride in bespoke work. They've seen tools that claimed to help and ended up adding overhead. They'll read a pattern library and see a path to being turned into a configuration operator rather than a problem-solver. That skepticism is earned.
What changed my thinking was reframing the ask. Pattern libraries don't replace creative work. They eliminate the drudgery beneath it. When Sarah doesn't have to debug OAuth rate limiting for the twelfth time, she can spend that week on the novel problem—the real-time feature pipeline the customer didn't even know was possible.
The governance model matters as much as the technology. Pattern contribution should be voluntary and credited. FDEs should control what gets extracted. Quality gates should be strict enough that the library stays useful rather than becoming a junk drawer. If the platform feels like surveillance, it fails. If it feels like leverage, it sticks.
The Hidden Cost: Knowledge That Walks Out the Door
There's a second-order problem that the efficiency argument misses.
When an FDE finishes a deployment and moves to the next customer, they take their mental model with them. The decisions they made—why they chose one authentication approach over another, which data quality checks actually matter in financial services, how to handle schema drift in a streaming pipeline—none of that is captured. It lives in their head until they leave the company, at which point it's gone.
This isn't unique to FDE work. It's the knowledge externalization problem that every knowledge-intensive organization faces. What's different is the stakes. A senior FDE's embedded knowledge represents months of hard-won learning in customer environments that cost hundreds of thousands of dollars to enter. Losing it isn't just an HR problem. It's a competitive one.
FDE Infrastructure creates a forcing function for knowledge capture. When a TelemetryFeed resource is attached to a deployment, the system logs error patterns, performance anomalies, and integration decisions automatically. When an FDE proposes a new primitive, they're encoding their judgment into something the next person can reuse and critique. The knowledge stops being purely personal.
What surprised me in designing this was how much the governance structure matters here. If pattern contribution is mandatory, FDEs write the minimum to satisfy the requirement and move on. If it's voluntary but tracked and credited—if "Sarah Chen contributed the Salesforce OAuth primitive used in 47 deployments"—it becomes career capital. The incentive and the organizational need align.
The Structural Argument
I'm convinced FDE Infrastructure becomes a recognized category within two years. The forces driving this are too strong.
FDE headcount is growing faster than any other engineering discipline. The costs are becoming hard to justify without efficiency multipliers. And the underlying pattern—bespoke field work gradually abstracted into platform primitives—is exactly how every mature engineering practice has scaled before. We've seen it in DevOps, in platform engineering, in MLOps. FDE is next.
The open questions are about who builds it and whether they build it right. Palantir has internal solutions that won't be productized. Cloud providers could offer primitive marketplaces, but they'll optimize for their own infrastructure rather than FDE workflows. My bet is an open-core model: the core operator and primitive library as open source, enterprise features for security, compliance automation, and advanced extraction. FDEs adopt tools they can inspect and extend. That's not optional.
Sarah left that client with working software and a satisfied customer. She also left carrying two weeks of accumulated knowledge that lived only in her head, and exhaustion that took her a week to shake. With the right infrastructure, the next FDE facing that integration challenge would start from a proven primitive, finish in days rather than weeks, and leave her insights behind for the team.
The exorbitant tax is real. The question is whether we build the infrastructure to manage it before it breaks the model.