Docling: The Complete Guide to AI-Powered Document Processing and Parsing
A comprehensive, step-by-step guide to Docling: the open-source, AI-powered document processing and parsing library. Learn installation, configuration, advanced features, and seamless AI integrations. Perfect for developers building document analysis and automation solutions.
Introduction
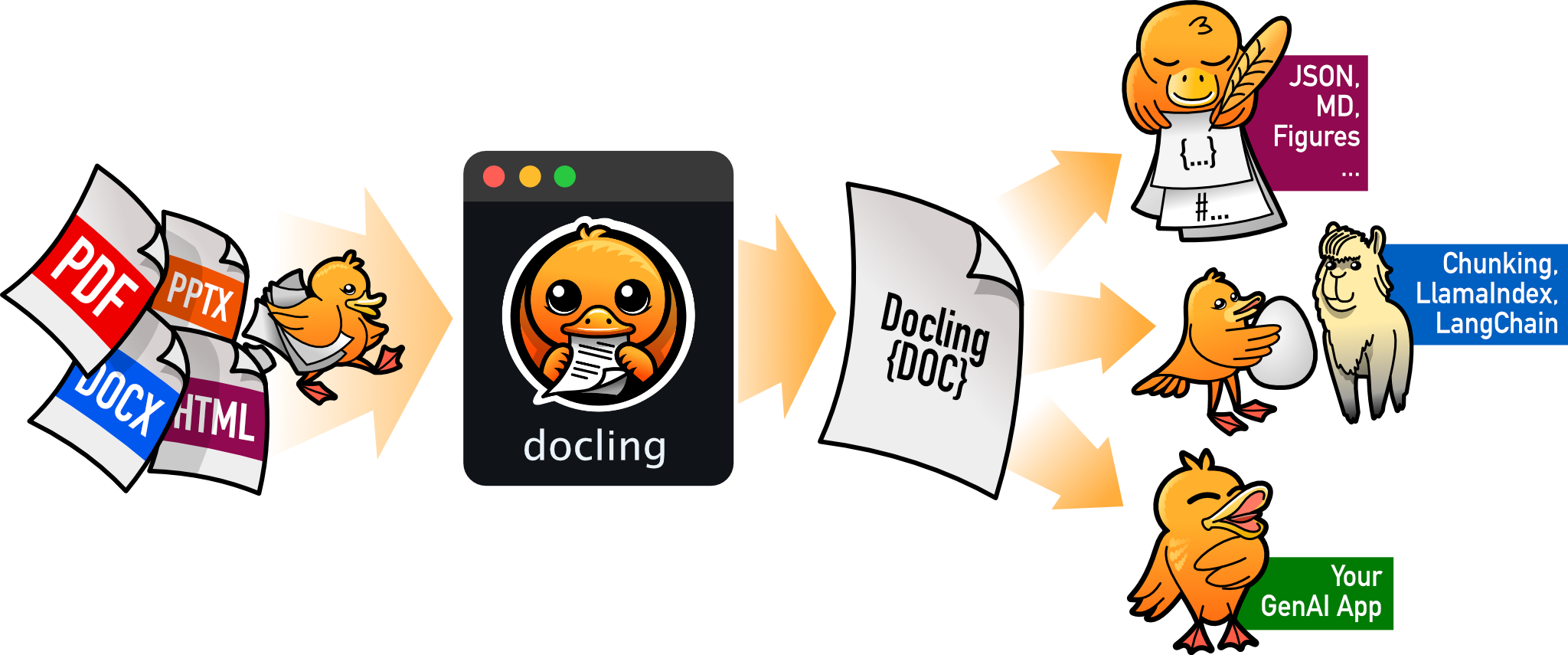
Docling is a powerful document processing library that simplifies parsing diverse formats — including advanced PDF understanding — and provides seamless integrations with the generative AI ecosystem. Developed by IBM Research and hosted by the LF AI & Data Foundation, Docling transforms how developers handle document processing in AI applications.
Table of Contents
Key Features
- Multi-Format Support: PDF, DOCX, PPTX, XLSX, HTML, WAV, MP3, images (PNG, TIFF, JPEG), and more
- Advanced PDF Understanding: Page layout, reading order, table structure, code, formulas, image classification
- Unified Document Format: Expressive DoclingDocument representation
- Multiple Export Options: Markdown, HTML, DocTags, and lossless JSON
- Local Execution: Secure processing for sensitive data and air-gapped environments
- AI Integrations: Plug-and-play support for LangChain, LlamaIndex, Crew AI & Haystack
- Extensive OCR Support: Multiple OCR engines for scanned PDFs and images
- Visual Language Models: Support for SmolDocling and other VLMs
- Audio Processing: Automatic Speech Recognition (ASR) models
Installation & Setup
Basic Installation
pip install docling
Works on macOS, Linux, and Windows, with support for both x86_64 and arm64 architectures.
CPU-Only Installation (Linux)
# For Linux systems with CPU-only support
pip install docling --extra-index-url https://download.pytorch.org/whl/cpu
macOS Intel (x86_64) Installation
For Intel-based Macs, use compatible PyTorch versions:
# For uv users
uv add torch==2.2.2 torchvision==0.17.2 docling
# For pip users
pip install "docling[mac_intel]"
# For Poetry users
poetry add docling
OCR Engine Setup
Docling supports multiple OCR engines:
| Engine | Installation | Usage |
|---|---|---|
| EasyOCR | Default or pip install easyocr |
EasyOcrOptions |
| Tesseract | System dependency | TesseractOcrOptions |
| RapidOCR | pip install rapidocr onnxruntime |
RapidOcrOptions |
| OnnxTR | pip install "docling-ocr-onnxtr[cpu]" |
OnnxtrOcrOptions |
Tesseract Installation
macOS (via Homebrew):
brew install tesseract leptonica pkg-config
TESSDATA_PREFIX=/opt/homebrew/share/tessdata/
echo "Set TESSDATA_PREFIX=${TESSDATA_PREFIX}"
Debian-based systems:
apt-get install tesseract-ocr tesseract-ocr-eng libtesseract-dev libleptonica-dev pkg-config
TESSDATA_PREFIX=$(dpkg -L tesseract-ocr-eng | grep tessdata$)
echo "Set TESSDATA_PREFIX=${TESSDATA_PREFIX}"
RHEL systems:
dnf install tesseract tesseract-devel tesseract-langpack-eng tesseract-osd leptonica-devel
TESSDATA_PREFIX=/usr/share/tesseract/tessdata/
echo "Set TESSDATA_PREFIX=${TESSDATA_PREFIX}"
Basic Usage
Simple Document Conversion
from docling.document_converter import DocumentConverter
# Initialize converter
converter = DocumentConverter()
# Convert document
result = converter.convert("path/to/document.pdf")
# Export to Markdown
markdown_content = result.document.export_to_markdown()
print(markdown_content)
Batch Processing
from docling.document_converter import DocumentConverter
import os
converter = DocumentConverter()
# Process multiple documents
document_paths = ["doc1.pdf", "doc2.docx", "doc3.pptx"]
for doc_path in document_paths:
result = converter.convert(doc_path)
# Save as JSON
output_path = f"{os.path.splitext(doc_path)[0]}.json"
with open(output_path, 'w') as f:
f.write(result.document.export_to_json())
OCR Configuration
from docling.datamodel.pipeline_options import PipelineOptions, TesseractOcrOptions
from docling.document_converter import DocumentConverter
# Configure OCR options
pipeline_options = PipelineOptions()
pipeline_options.do_ocr = True
pipeline_options.ocr_options = TesseractOcrOptions() # Use Tesseract
# Initialize converter with OCR
converter = DocumentConverter(pipeline_options=pipeline_options)
# Process scanned document
result = converter.convert("scanned_document.pdf")
print(result.document.export_to_markdown())
Advanced Features
Custom Export Formats
from docling.document_converter import DocumentConverter
converter = DocumentConverter()
result = converter.convert("document.pdf")
# Export to different formats
markdown = result.document.export_to_markdown()
html = result.document.export_to_html()
json_data = result.document.export_to_json()
doctags = result.document.export_to_doctags()
# Save exports
with open("output.md", "w") as f:
f.write(markdown)
with open("output.html", "w") as f:
f.write(html)
with open("output.json", "w") as f:
f.write(json_data)
Audio Processing with ASR
from docling.document_converter import DocumentConverter
from docling.datamodel.pipeline_options import PipelineOptions
# Configure for audio processing
pipeline_options = PipelineOptions()
converter = DocumentConverter(pipeline_options=pipeline_options)
# Process audio file
result = converter.convert("audio_file.wav")
transcript = result.document.export_to_markdown()
print(f"Transcript: {transcript}")
Visual Language Model Integration
from docling.document_converter import DocumentConverter
from docling.datamodel.pipeline_options import PipelineOptions
# Configure for VLM processing
pipeline_options = PipelineOptions()
pipeline_options.use_vlm = True # Enable Visual Language Model
converter = DocumentConverter(pipeline_options=pipeline_options)
# Process document with VLM
result = converter.convert("complex_document.pdf")
structured_content = result.document.export_to_json()
print(structured_content)
AI Framework Integrations
LangChain Integration
from docling.document_converter import DocumentConverter
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import FAISS
from langchain.embeddings import OpenAIEmbeddings
# Convert document
converter = DocumentConverter()
result = converter.convert("document.pdf")
markdown_content = result.document.export_to_markdown()
# Create text chunks for RAG
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200
)
chunks = text_splitter.split_text(markdown_content)
# Create vector store
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_texts(chunks, embeddings)
LlamaIndex Integration
from docling.document_converter import DocumentConverter
from llama_index.core import Document, VectorStoreIndex
from llama_index.core.node_parser import SimpleNodeParser
# Convert document
converter = DocumentConverter()
result = converter.convert("document.pdf")
markdown_content = result.document.export_to_markdown()
# Create LlamaIndex document
document = Document(text=markdown_content)
# Parse and index
node_parser = SimpleNodeParser()
nodes = node_parser.get_nodes_from_documents([document])
index = VectorStoreIndex(nodes)
# Query the index
query_engine = index.as_query_engine()
response = query_engine.query("What is the main topic of this document?")
print(response)
Haystack Integration
from docling.document_converter import DocumentConverter
from haystack import Document
from haystack.document_stores import InMemoryDocumentStore
from haystack.nodes import DensePassageRetriever, FARMReader
from haystack.pipelines import ExtractiveQAPipeline
# Convert document
converter = DocumentConverter()
result = converter.convert("document.pdf")
markdown_content = result.document.export_to_markdown()
# Create Haystack document
document = Document(content=markdown_content)
# Initialize document store and add document
document_store = InMemoryDocumentStore()
document_store.write_documents([document])
# Create QA pipeline
retriever = DensePassageRetriever(document_store=document_store)
reader = FARMReader(model_name_or_path="deepset/roberta-base-squad2")
pipeline = ExtractiveQAPipeline(reader, retriever)
# Ask questions
result = pipeline.run(query="What are the key findings?", params={"Retriever": {"top_k": 3}})
print(result['answers'])
Conclusion
Docling represents a significant advancement in document processing technology, offering developers a comprehensive toolkit for handling diverse document formats with AI-powered understanding. Its seamless integration with popular AI frameworks, extensive OCR support, and local execution capabilities make it an ideal choice for building robust document processing pipelines in modern AI applications.
Whether you're building RAG systems, document analysis tools, or content extraction pipelines, Docling provides the foundation for reliable, scalable document processing with cutting-edge AI capabilities.
For more expert insights and tutorials on AI and automation, visit us at decisioncrafters.com.
